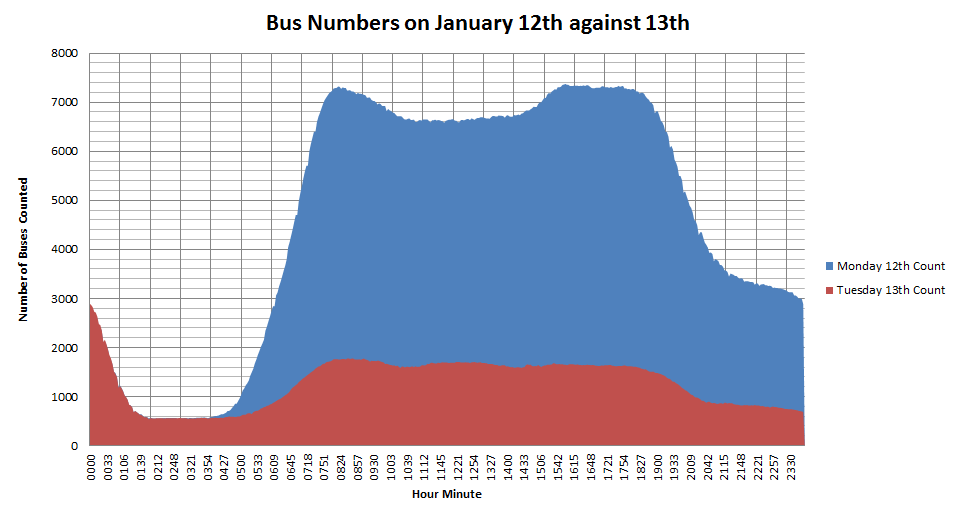
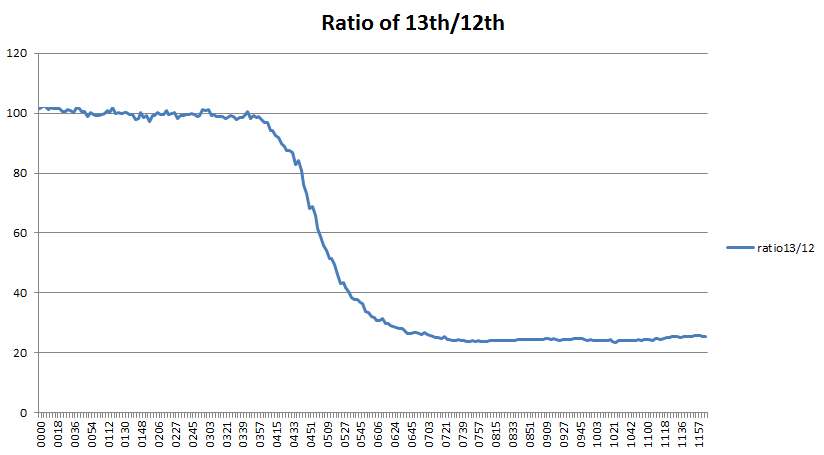
Now that all 15 gnomes, otters, bats and honeybees are deployed in the Olympic park [link], I wanted to create something that was portable enough to take to an exhibition and that showed the geographic extent of the deployment. The talesofthepark.com website has a map, but I wanted to create something physical.

My first thought was a Unity application with a 3D model of the park using the conversation data that we’ve collected so far. The idea was to zoom in on one of the creatures, show the conversation with the park visitor using speech bubbles, then zoom back out and repeat for the next conversation.
Luckily, we have 3D scans of all the printed and painted models which were reconstructed using Autodesk Remake.
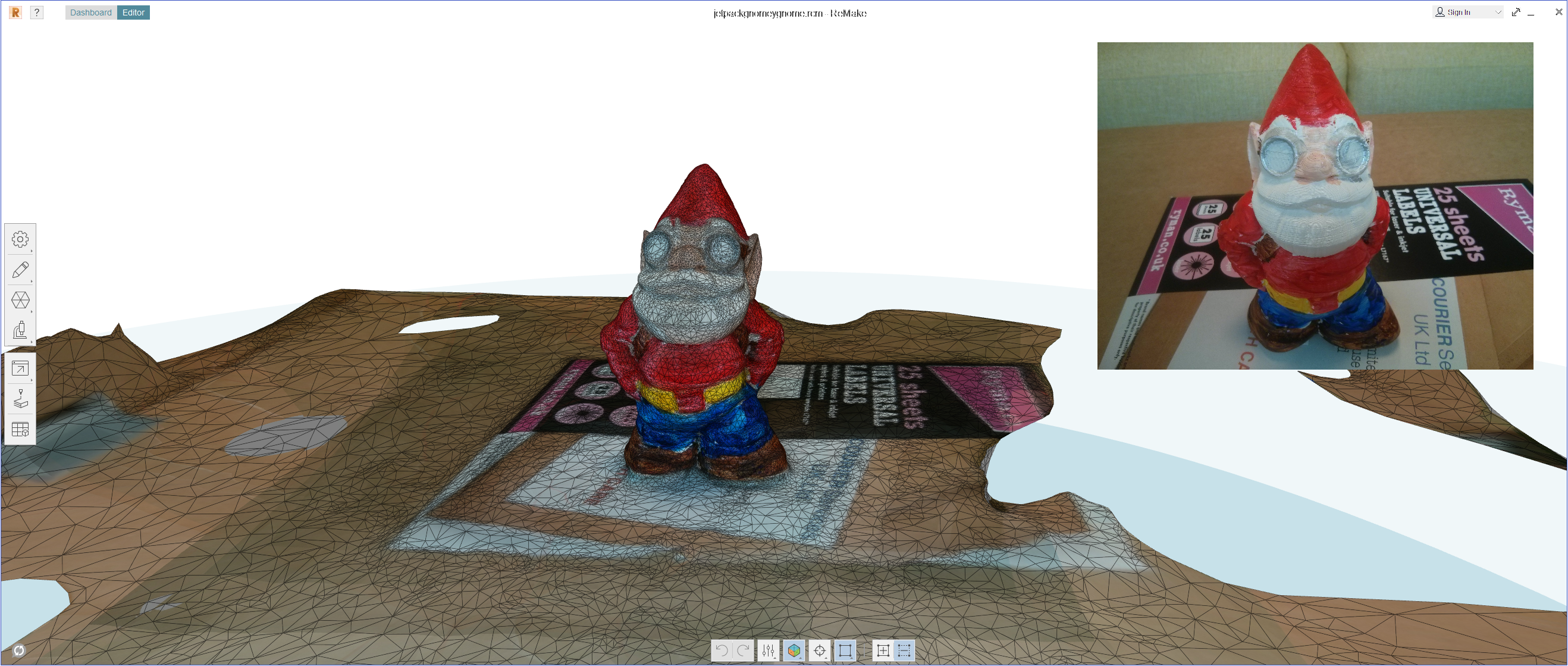

The only problem was the park model to show where the creatures are located. This is where I hit on the idea of using the Environment Agency Lidar data which was flown for the park in 2012:
https://data.gov.uk/dataset/lidar-point-cloud
It’s relatively easy to load ASC format DEM and DTM files into Unity as it’s a text format, so I wrote some classes to load the data and generate a “Terrain” object which I could drag into my scene graph. Having done this, I then wanted to do the same with the point cloud data that they have released in LAZ format. This was a bit more involved and took a couple of days work. I used the “LASTools” utility to convert the compressed LAZ file into an uncompressed LAS one and ran it through my Unity Lidar reader.
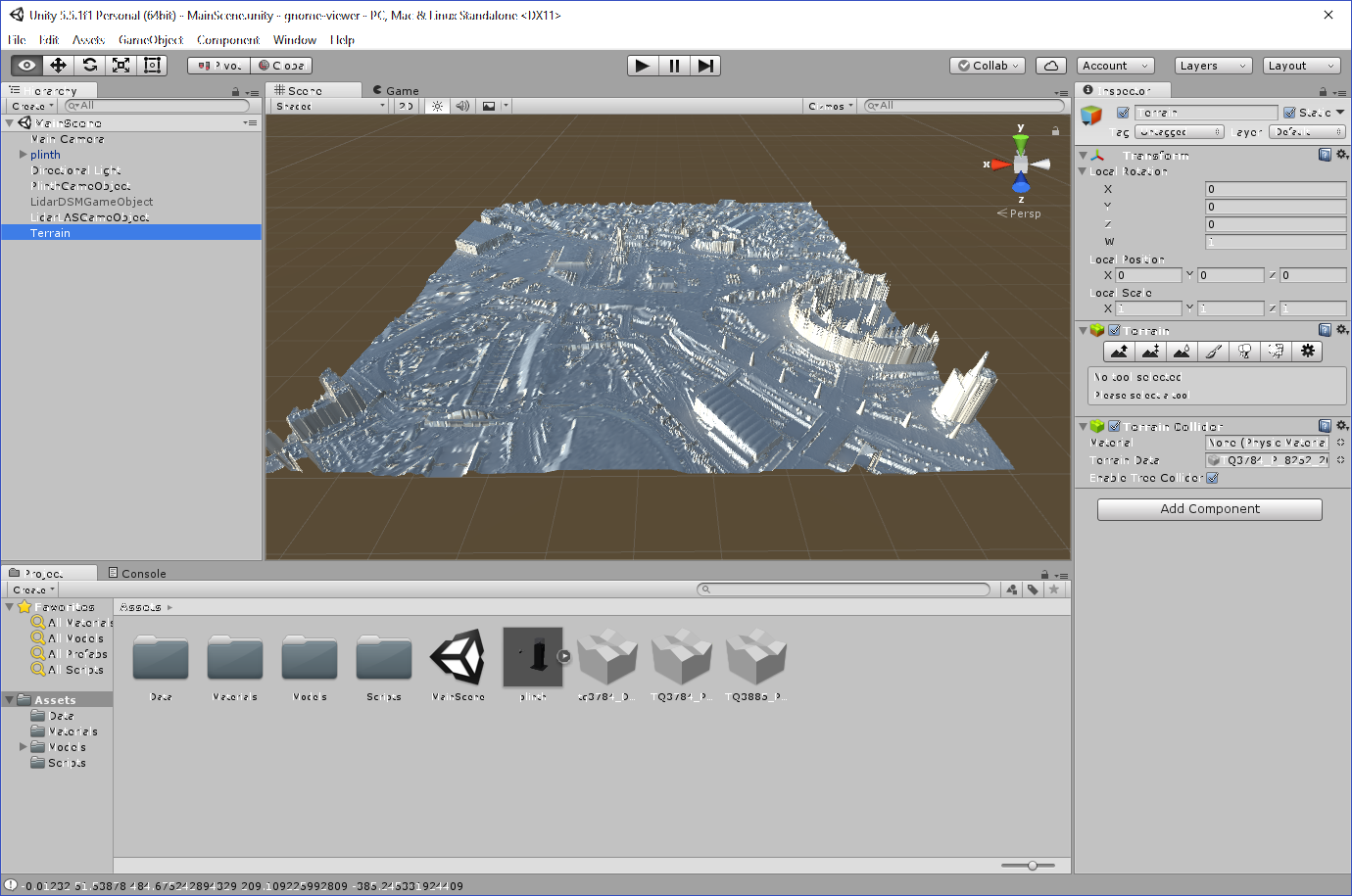
Although I had a 3D model of the gnome on the plinth and could now have built my “gnome viewer” application, I was really interested in whether I could build a physical exhibit for the upcoming PETRAS conference.

The only missing element was that Unity doesn’t provide any functions to export terrain meshes, so I had to spend a couple of hours writing an OBJ file exporter. At this point, I now had all the pieces in place to generate Lidar tiles, export them as OBJ meshes and prepare them for 3D printing using CURA.
This is my first attempt:

While this isn’t bad for a first attempt, I needed it bigger as I wanted to see more resolution on the buildings. In order to do this I needed to split the tile above into 16 (4×4), scale the 1/16th tile up and print them individually. These 1/16th tiles were printed at a scale of 6.2cm x 6.2cm, which came from loading them into CURA, whereby the size was too big to fit the print bed. Rescaling by 25% of the original size gave me a tile that fitted the printer and took around 2 hours to print. The small tiles are about 2.5 times the size of the original 10cm one, allowing me to print the whole park map in about 10 days. More importantly, it’s a portable, so I can take it on a train to exhibitions.





Now that I have the methodology to do this for anywhere in the UK using the EA Lidar data, I’m thinking about tidying up the code and publishing it on the Unity App Store. It’s quite a useful thing to have and I’m sure other people would be interested in using it.